Unterabschnitte
State Value Function
Die State Value Function bewertet eine Situation des Systems. Es wird bewertet, was wir aufgrund der Policy 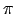 aus diesem Status für ein Return haben können.
aus diesem Status für ein Return haben können.
Action Value Function
Die Aktion Value Function bewertet eine Aktion des Agentens.